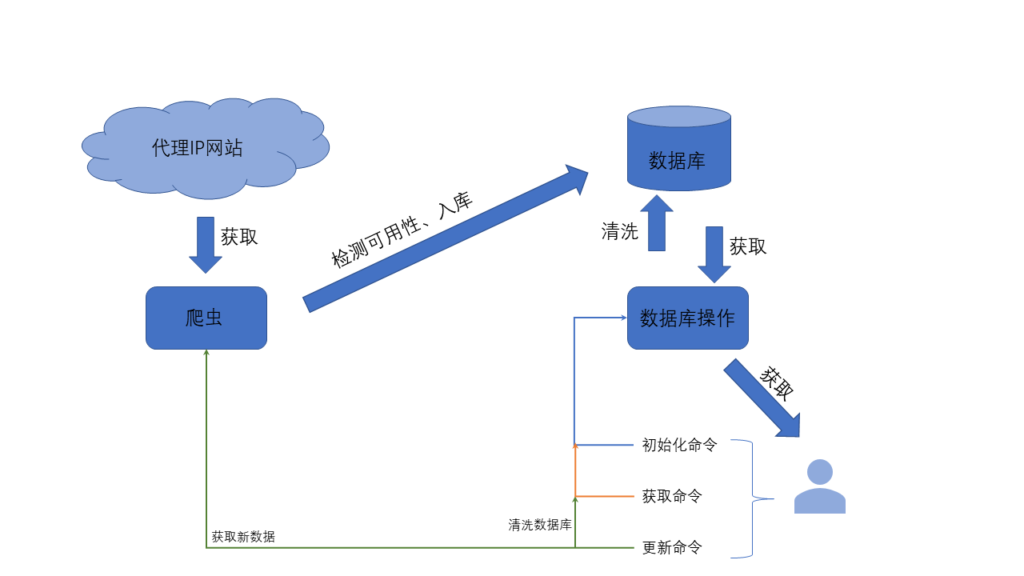
对某个网站进行高频次采集时经常会遇到IP被封的情况,这时候需要使用代理IP了。建立一个数据库,提供稳定可用的代理IP给爬虫使用,也是主要任务之一。
主要功能:
- 从代理网站获取代理IP
- 对代理IP进行检测,检测是否可用。检测方法是访问一稳定的网站,例如百度,腾讯等,查看状态码。
- 写入数据库
- 清洗数据库,剔除不可用的IP
- 获取一条可用的代理
数据库只需要一个表,表中只要一列:
CREATE TABLE IF NOT EXISTS {} (IP_PORT TEXT NOT NULL PRIMARY KEY);逻辑图:
数据来源:
http://www.kuaidaili.com/free/ http://www.66ip.cn/ http://www.xicidaili.com/nn/ http://www.ip3366.net/free/ http://www.proxy360.cn/Region/China http://www.mimiip.com/ http://www.data5u.com/free/index.shtml http://www.ip181.com/ http://www.kxdaili.com/
使用:
查看demo.py文件
Util.Refresh():数据库和新的数据需要主动调用此函数更新
Util.Get():调用可获取一条可用的代理,Util.Get()返回的代理:
{‘http’: ‘http://115.159.152.130:81‘, ‘https’: ‘https://115.159.152.130:81′}
requests可以直接使用:requests.get(url,proxies=Util.Get(),headers={})
Config.py 部分:
如果你还有代理网站可以添加,请添加在Url_Regular字典中。
代理IP网址和对应的正则式,正则式一定要IP和Port分开获取,例如[(192.168.1.1, 80), (192.168.1.1, 90),]
只抓取首页,想要抓取首页以后页面的可以将链接和正则式贴上来,例如,将某网站的1、2、……页的链接和对应的正则式分别添加到Url_Regular字典中。
添加正则式之前请先在 站长工具-正则表达式在线测试 测试通过后添加
Github:
ZKeeer/IPProxy——爬虫所需要的IP代理,抓取八个网站的代理IP检测/清洗/入库/更新,添加调用接口
测试:
按照十五分钟一次刷新的速度,半天时间可以获得上千可用IP
声明:
不要高频次刷代理IP,不要给以上数据来源服务器造成过大的压力
没获取到ip,只打印出了、
{}
0
求解,,
1.确保网络通畅,2.说清楚是直接打印出了{},0 还是过了一段时间才打印出的?
问题已经查清解决,请从Github上下最新版
[…] 我在上篇文章《获取爬虫所需要的代理IP》中的代码中就有收集的UserAgent,见Github 。 […]
博主,你抓ip的时候为什么只爬首页的?可以直接构造每页的链接遍历每页的ip吗?
因为当时为了节约代码量,设计的是{网址:正则式}的配置,用循环就可以把配置里面的所有网站提取完,不用每个网站都单独写代码。如果需要第二页,可以把第二页的链接和正则式配置添加到对应位置,效果是一样的。
博主正则用的简直了,超溜的感觉!
其实我的正则相比于我推荐的那位大哥,渣得很,我没学原理
厉害了我的安卓机