本文首发:ZKeeer’s Blog——简单爬虫的通用步骤
代码基于 python3.5
多图预警,长文预警
欢迎转载
知识点很多,适合小白,大神绕路
填坑系列一:简单爬虫的通用步骤——多线程/多进程爬虫示例
填坑系列二:待定
.
.
.

1.获取数据
爬虫,就是要千方百计地装成浏览器从网站骗数据。——我说的
1.1从requests.get()说起
最开始一个简单的爬虫就是调用python的requests模块,使用get函数。(为了不祸害别人网站,我以自己的网站为例)
import requests
url_response = requests.get("http://zkeeer.space")
print(url_response.status_code, url_response.text)这里get函数从给出的URL获取数据,打印出状态码和获取的内容看看。
200 <!DOCTYPE html> <html lang="zh-CN"> <head>......
状态码200,说明平稳落地。后面是获取到的网页。
这里要说明一点,url_response.text 和 url_response.content的区别:
.text返回的是Unicode类型,.content返回的是bytes型也就是传说的二进制的数据。当需要的数据是文本时,最好用.text,当你需要下载图片时,要用.content
上面是.text返回的值,下面打印出来.content的值让大家看看。
200 b'<!DOCTYPE html>\r\n<html lang="zh-CN">\r\n <head>
看到前面的小b以及后面赤裸裸的\r\n了么?
我的博客挺简单没有那么大访问量,也不需要限制访问量,也不需要严查你的IP,UserAgent,Cookie等。当你需要大量,高频次访问,而且访问的还是淘宝这样的商业网站,这时候你就需要伪装了,不能只是赤裸裸的用个get加个url,就向网站大喊:“我!浏览器!给数据!” 也就我的博客这么好心给你,淘宝早就会“淘宝不想理你,并向你扔了个大创可贴”。
1.2学会使用火狐浏览器开发者工具
如何伪装一个浏览器?
学习当然都是从模仿开始——也是我说的!
这里使用的是火狐浏览器开发者工具,别听这么高大上,其实就是打开火狐浏览器按F12!
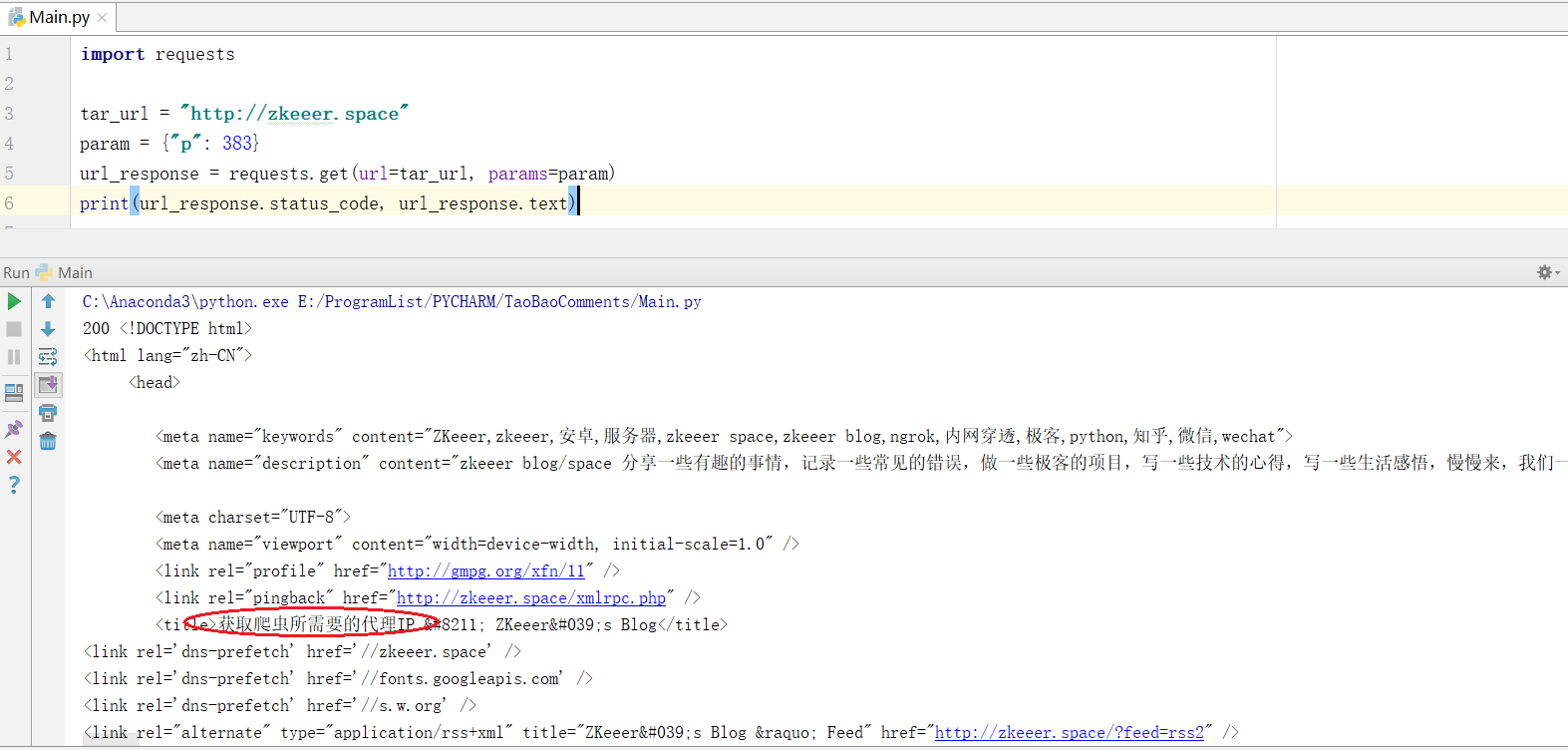
第一步输入网址进入我的博客,http://zkeeer.space 然后按F12,找到网络这一栏。它会提示你重新载入,那就按一下F5,刷新一下。
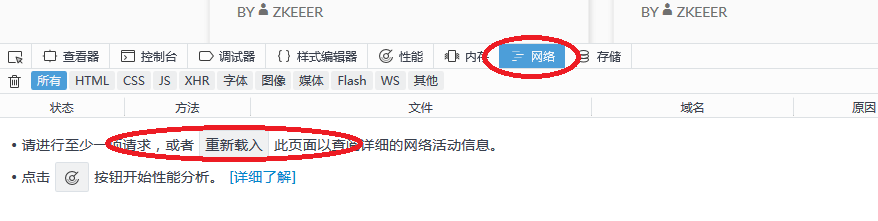
注意以下几栏。然后找到并点开我们需要的,也就是第一个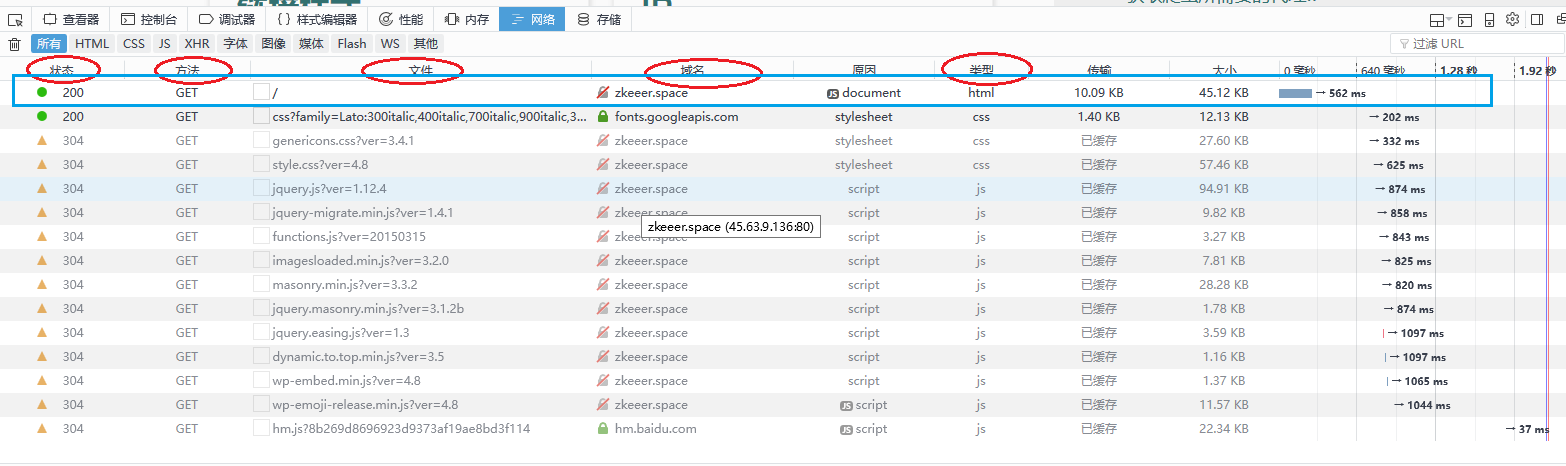
右侧会出来对应的详细信息。包括:消息头,Cookie,参数,响应,耗时,堆栈跟踪。
首先requests.get(url, params=None, **kwargs),下面的顺序按照参数顺序,一一来。
1.3requests.get()参数一:url
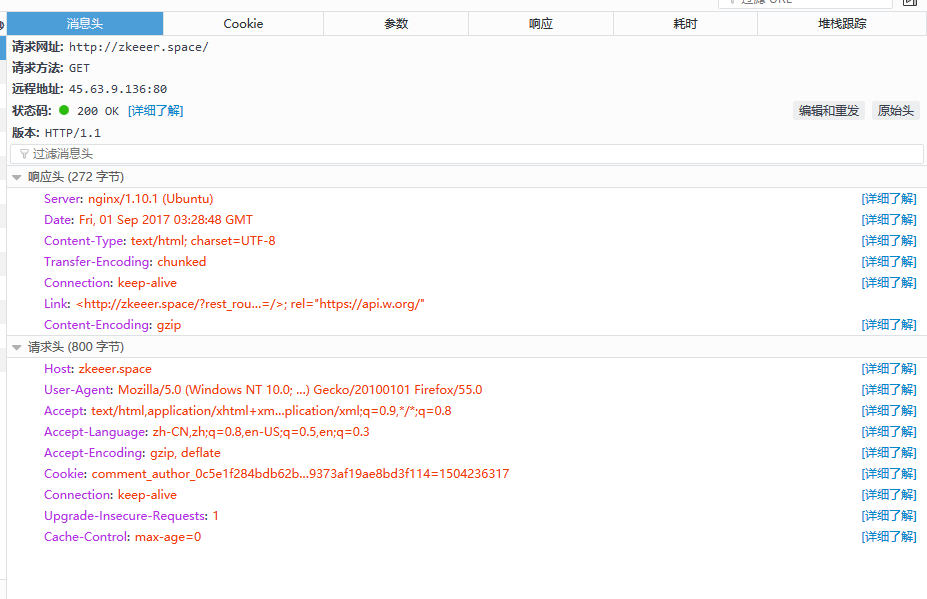
消息头这一栏给出的请求方法是GET,即请求时使用requests.get(),如果这里是POST,对应使用requests.post()。get函数的url,即请求头的Host,这里是“zkeeer.space”
1.4requests.get()参数二:params
get(url, params=None, **kwargs)中params,是构成网址中一些参数,网址链接“?”后面的那些参数。举个栗子:我的一篇文章链接是http://zkeeer.space/?p=383 那么后面p=383就是get 的参数(当然你也可以直接访问http://zkeeer.space/?p=383,而不需要参数)。
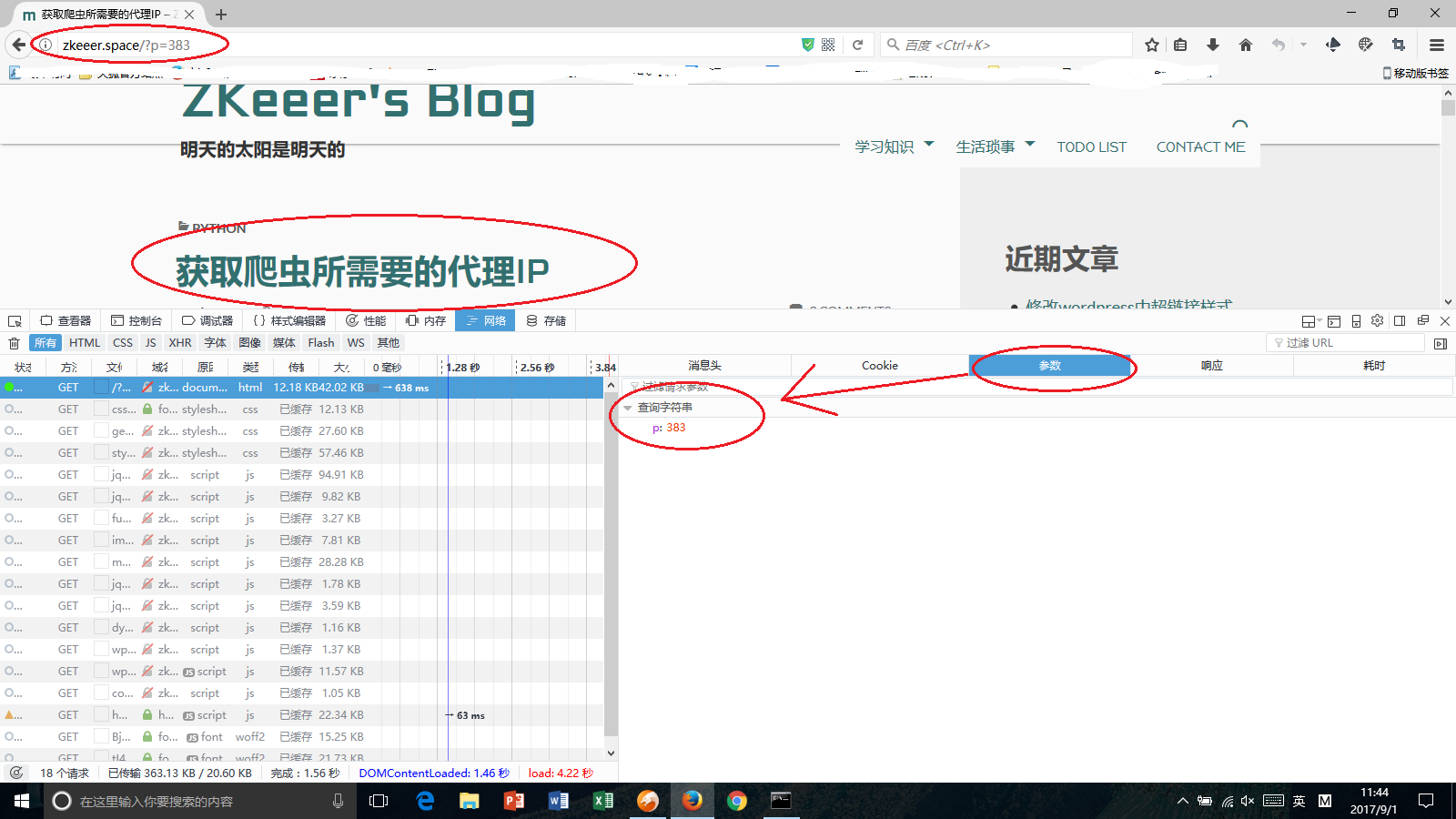
需要把这里列举的参数都写到params里面,哪怕是该参数没有值。
那么一开头我们那几行代码就应该这么写了。
import requests
tar_url = "http://zkeeer.space" # 目标网页
param = {"p": 383} # 请求头的参数
url_response = requests.get(url=tar_url, params=param)
print(url_response.status_code, url_response.text)这样获取到的页面就是“zkeeer.space/?p=383”对应的文章了。
1.5requests.get()参数三:headers
可能会有疑问,get(url, params=None, **kwargs)并没有headers这个参数啊。这个包含在**kwargs里面,同样还有另一常用的proxies,待会儿会说到。
headers应该写什么呢?下图所示的消息头中的请求头即是这里的headers参数。
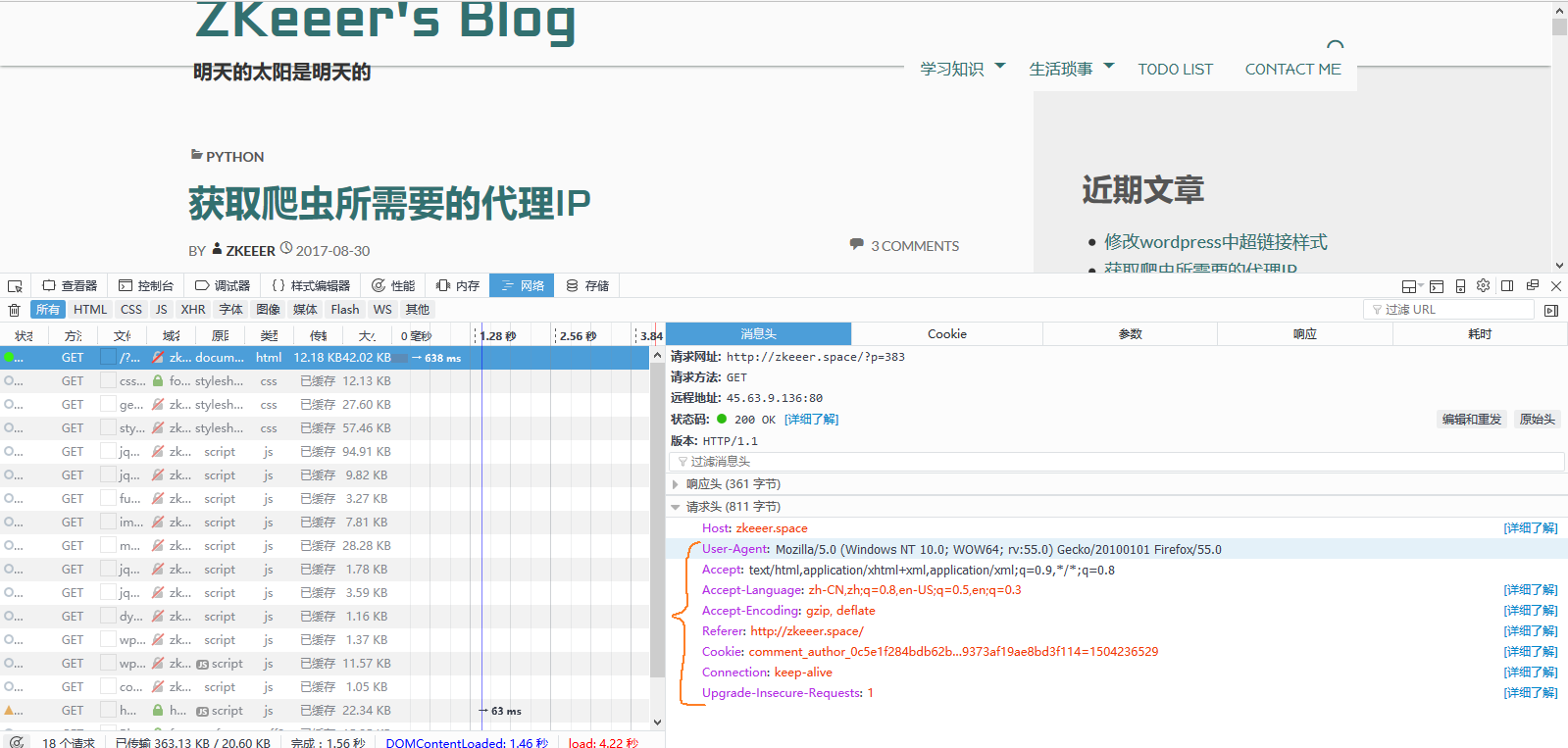
跟参数一样,需要把请求头的所有信息写入headers(如果网站不查cookie的话,cookie没必要写)。如果对这些参数不了解,可以点击后面对应的详细了解,介绍的很详细。
上面的几行代码又要进化了。
import requests
tar_url = "http://zkeeer.space" # 目标网页
param = {"p": 383} # 请求头的参数
header = { # 请求头部
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://zkeeer.space/",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
url_response = requests.get(url=tar_url, params=param, headers=header)
print(url_response.status_code, url_response.text)这样一来就比较完备了。
但是这样情况下,高频次访问对服务器造成压力了,可能会分析哪个UserAgent访问次数最多,发现是你在狂刷人家网站,这时候就有可能给你禁了这个UserAgent,这时候你需要更多的UserAgent随机挑选进行访问。
我在上篇文章《获取爬虫所需要的代理IP》中的代码中就有收集的UserAgent,见Github 。
可以使用random.choice()随便挑嘛。
1.6requests.get()参数四:proxies
上面提到了,这个参数是代理,对,是代理。当你使用随机UserAgent的人家没法封了。就会查你IP,发现这个IP刷爆了网站,直接就封了。这时候你要使用代理IP。
上面的代码又进化了呢!
import requests
tar_url = "http://zkeeer.space" # 目标网页
param = {"p": 383} # 请求头的参数
proxy = {"http": "http://{}:{}".format("221.8.186.249", "80"),
"https": "https://{}:{}".format("221.8.186.249", "80")} #代理IP
header = { # 请求头部
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://zkeeer.space/",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
url_response = requests.get(url=tar_url, params=param, proxies=proxy, headers=header)
print(url_response.status_code, url_response.text)问题又来了,长时间使用同一个代理IP,也会被封啊,我要获取大量代理IP,最好还是匿名或者高匿。这些代理IP从哪来的?我该怎么获取?上篇文章我写了如果获取大量代理IP以及使用:获取爬虫所需要的代理IP
如果需要高质量IP可以从代理网站或者淘宝买,大量,不贵。
1.7总结
至此,基本的获取网页已经差不多了,大多数网站你都可以畅行。尽管,也不能暴力访问一个网站,要有公德心嘛,我写爬虫还sleep(0.5)呢。
火狐浏览器的开发者工具很好用,希望大家能发挥其作用。
2.提取数据
获取完网页接下来应该提取数据了。获取网页的数据,我想提取网页中特定的文字,或者是数据,或者是图片,这就是网页主要提取的吧。
2.1提取文字
先说提取文字,强烈推荐正则表达式,太强大了。简直就是加特林哒哒哒哒冒蓝火的那种;正则在手,天下我有;当然我的水平仅限于能用,就不出来献丑了。大家按照网上的教程来就可以。当然你也可以用beautifulsoup。正则表达式和beautifulsoup这两种效率比较高。
2.2提取图片
以我博客中《获取爬虫所需要的代理IP》文章为例,提取其中的图片。提取网页中的图片,我们可以用提取文字的方式,用正则表达式获取图片链接。这时候,又用的get函数。跟获取网页一样,获取图片。记得前面说过的text和content的区别。这里要使用后者。那么如何保存一张图片呢?看下面的代码示例。
打开火狐浏览器开发者工具。这次使用的是查看器,而不是网络。一层层找到上面文章中的图片所在位置及相关链接。
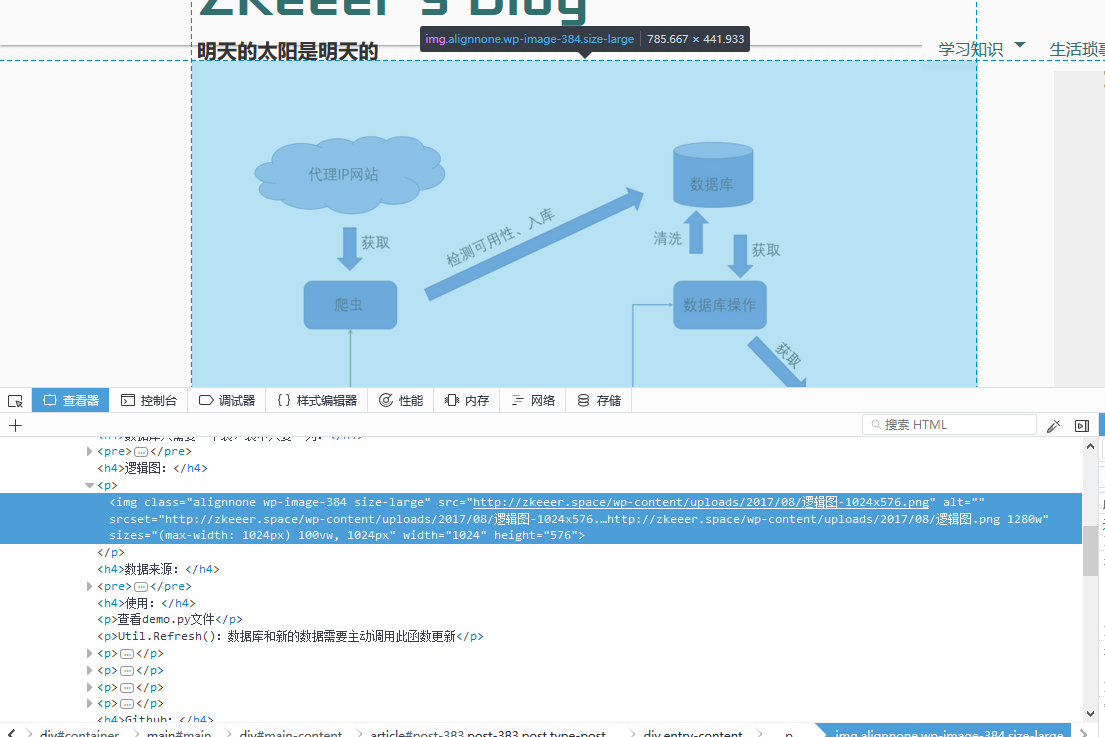
找到了<img>标签,这时可以右键查看网页源代码,查找一下看有多少是跟你目标相似的,看看如何区分
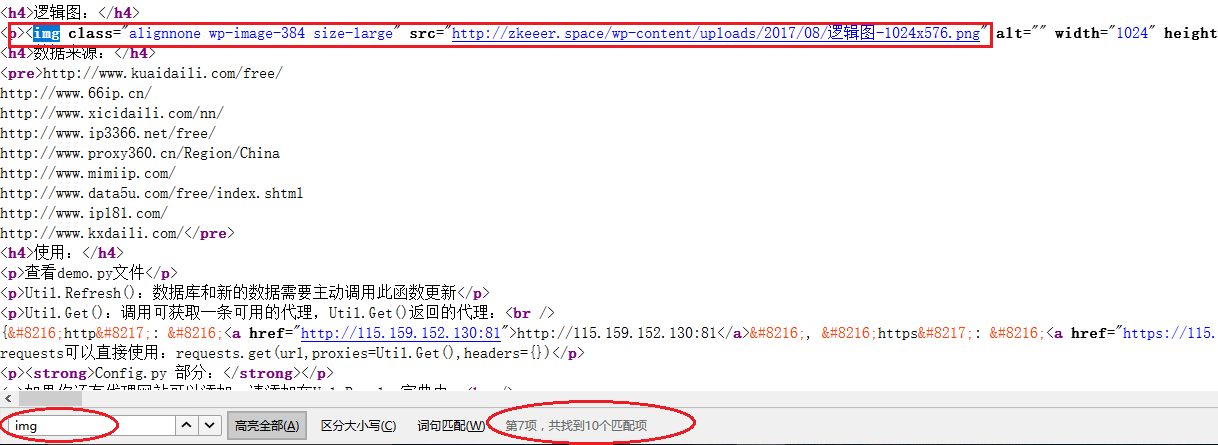
我找到了10项,但只有一项是我需要的,于是我把正则式写成了
<img class=\"[^\"]+\" src=\"([^\"]+)\"
这时候可以用 站长工具-正则表达式在线测试 测试下自己写的正则表达式是否正确
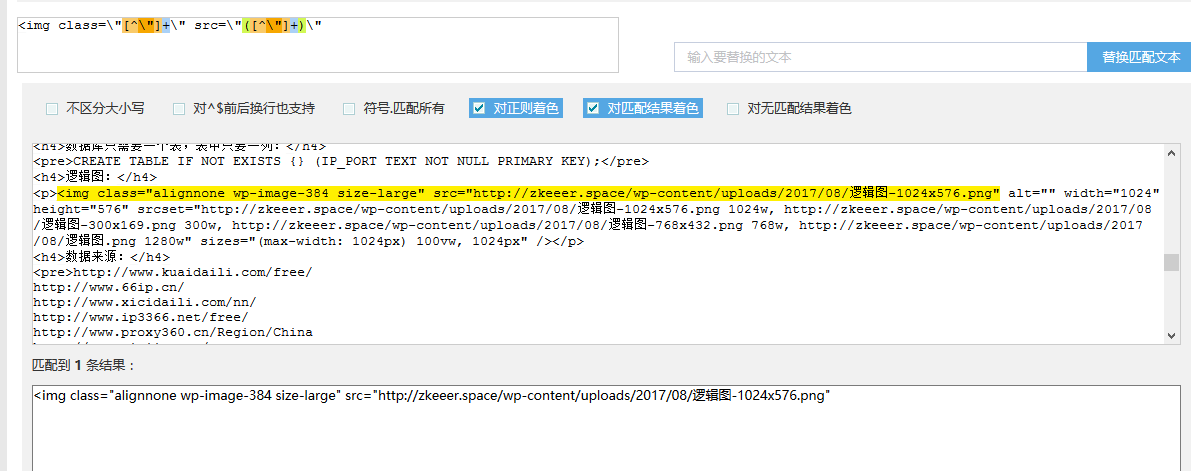
成功了!代码如下:
import re
import requests
tar_url = "http://zkeeer.space" # 目标网页
param = {"p": 383} # 请求头的参数
header = { # 请求头部
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://zkeeer.space/",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
url_response = requests.get(url=tar_url, params=param, headers=header)
img_url = re.findall(r"<img class=\"[^\"]+\" src=\"([^\"]+)\"", url_response.text)
print(img_url[0])输出结果:
http://zkeeer.space/wp-content/uploads/2017/08/逻辑图-1024x576.png
这样有了图片的链接,我们就可以使用链接获取并保存图片了。
一定要注意使用F12,并仔细查看请求头和参数!
一定要注意使用F12,并仔细查看请求头和参数!
一定要注意使用F12,并仔细查看请求头和参数!
import re
import requests
tar_url = "http://zkeeer.space" # 目标网页
param = {"p": 383} # 请求头的参数
header = { # 请求头部
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://zkeeer.space/",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
url_response = requests.get(url=tar_url, params=param, headers=header)
img_header = { # 请求头部
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://zkeeer.space/?p=383",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
# 获取图片链接
img_url = re.findall(r"<img class=\"[^\"]+\" src=\"([^\"]+)\"", url_response.text)[0]
# 从图片链接中提取图片名
img_name = re.findall(r"([^/]+.png)", img_url)[0]
# 请求
url_response = requests.get(url=img_url, headers=img_header)
# 保存图片
with open(img_name, "wb") as fw:
fw.write(url_response.content)运行程序查看得到的图片(我的vps配置特别低,速度特慢,轻喷。给Vultr的VPS打个广告,有优惠!)
好了,到这儿可以获取基本的网页信息了。而且高频次访问基本上不会被封。
你以为到这就结束了吗?
2.3提取动态加载的数据
在获取有些重要数据的时候。这些数据是动态加载的。这也是反爬虫的一种手段,下面我有提及反爬虫。
当我只获取这个网页的时候,根本不会显示这些数据。这个时候又要让你的爬虫装一次浏览器。当然不能说:我!浏览器!给数据! 这个时候你不光要卖萌,还要回答问题。快看快看,我是浏览器,我是可爱的浏览器,快给我数据啊。
这时候人家就问你,你是从哪儿(Refer)找到我的?你的鸡毛信(ID)呢?你从袖筒里排出几个参数,浏览器一看,哎呀,大兄弟,真的是你,快给你数据。这时候不要吭声,趁他不注意,拿了数据赶紧跑。

获取方式跟上面获取网页一样。同样是使用火狐。以淘宝米6商品评论为例,我随便找的,别说我软广:
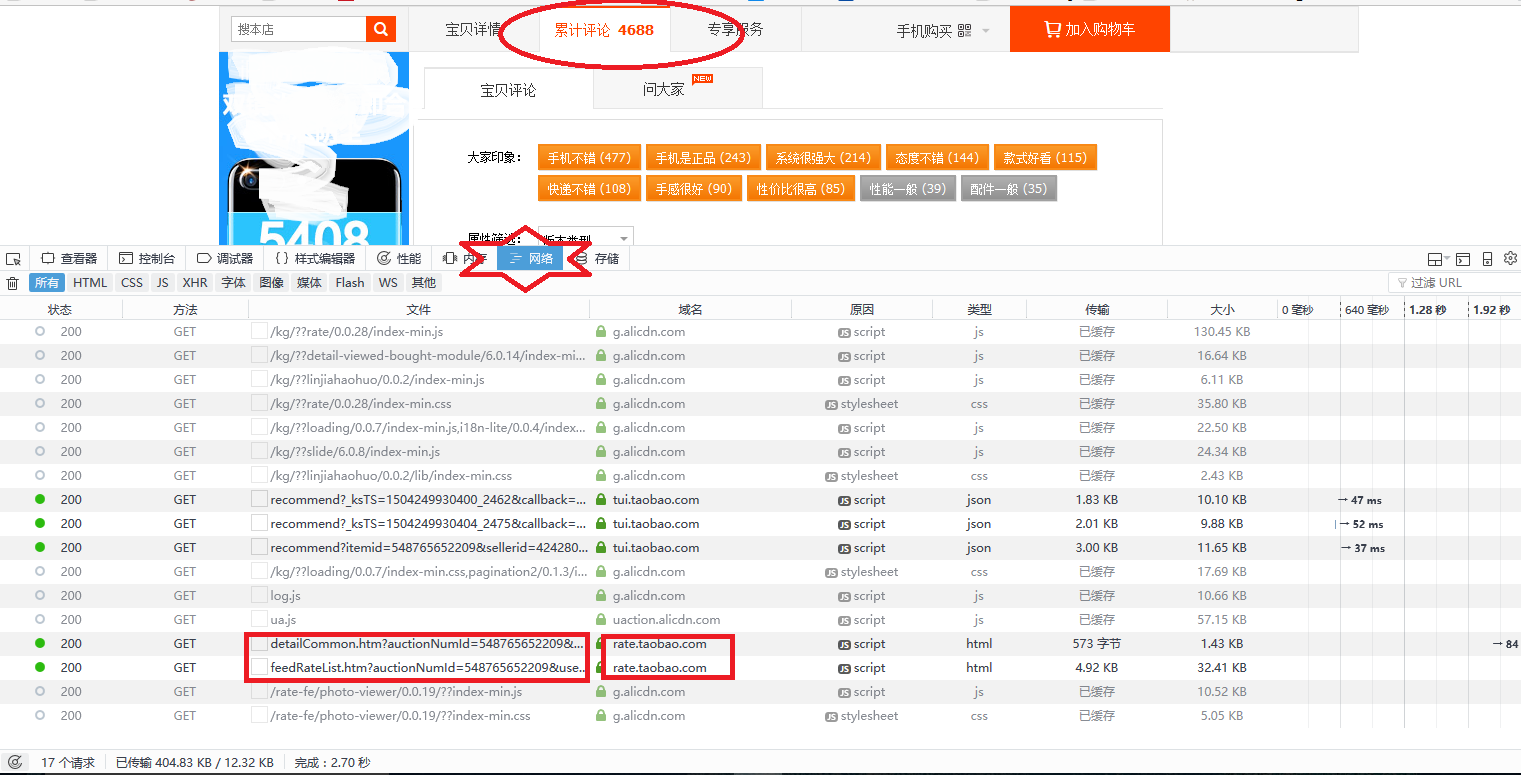
点击评论,然后看到网络这一栏,动态加载的内容就出来了,从域名里我找到了rate.taobao.com,对应左边两个文件,一个是detailCommon.htm 另一个是freeRateList.htm;我查看了下,分别对应评论中的大家印象和详细评论。查看哪儿?查看对应的响应内容。
这里就以“大家印象”为例:按照1.获取数据的步骤,获取到了如下结果:
import re
import requests
tar_url = "https://rate.taobao.com/detailCommon.htm"
# 商品链接
refer = "https://item.taobao.com/item.htm?spm=a230r.1.14.119.76bf523Zih6Ob&id=548765652209&ns=1&abbucket=12"
# 从商品链接中提取商品ID
NumId = re.findall(r"id=(\d+)\&", refer)
# 参数
param = {"auctionNumId": NumId,
"userNumId": "43440508",
"callback": "json_tbc_rate_summary"}
# 头部信息
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,ru;q=0.4',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': "1",
'Referer': refer,
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0"
}
try:
url_content = requests.get(url=tar_url, params=param, headers=header)
print("url_content: ", url_content.text)
except BaseException as e:
pass结果:
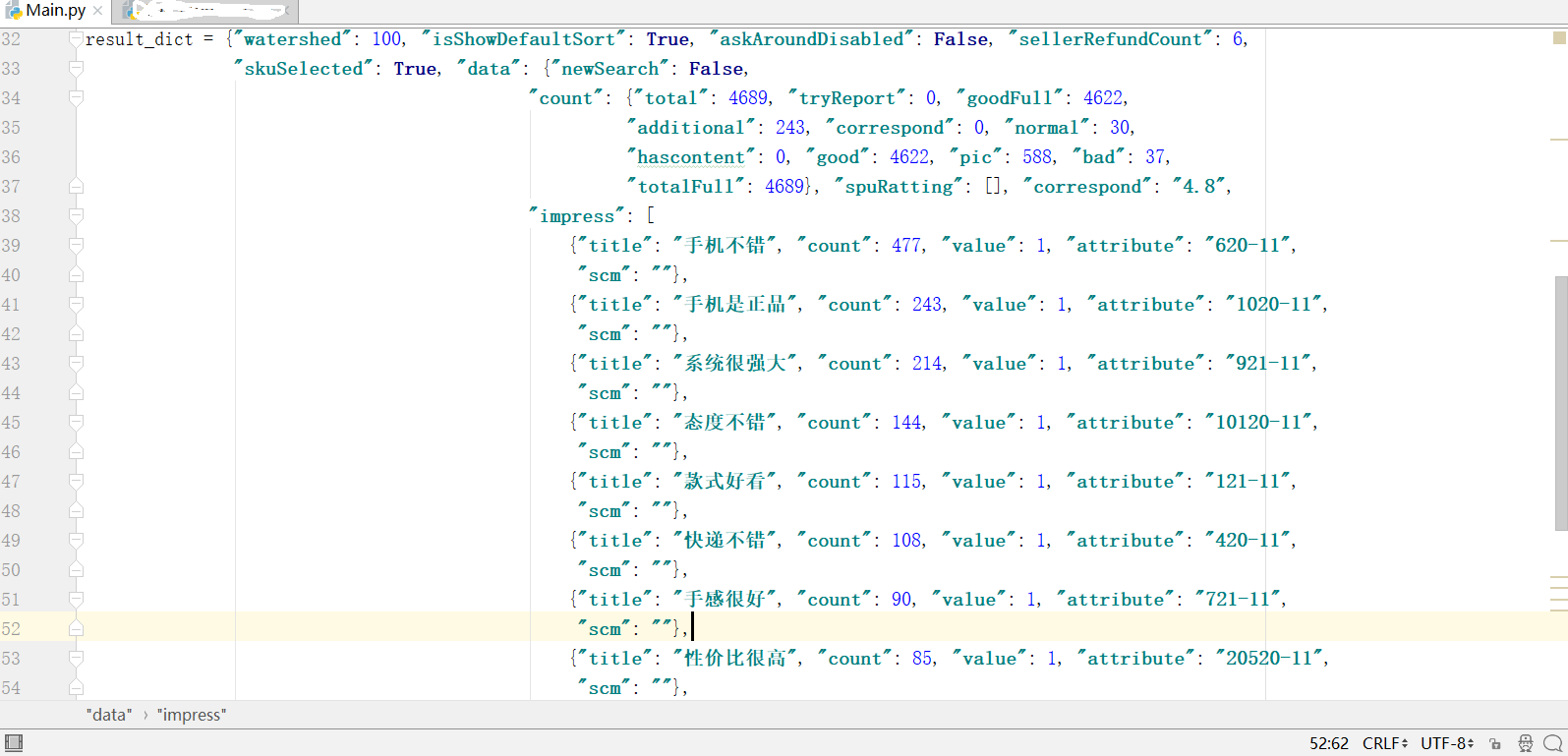
json_tbc_rate_summary({"watershed":100,"isShowDefaultSort":true,"askAroundDisabled":false,"sellerRefundCount":6,"skuSelected":true,"data":{"newSearch":false,"count":{"total":4689,"tryReport":0,"goodFull":4622,"additional":243,"correspond":0,"normal":30,"hascontent":0,"good":4622,"pic":588,"bad":37,"totalFull":4689},"spuRatting":[],"correspond":"4.8","impress":[{"title":"手机不错","count":477,"value":1,"attribute":"620-11","scm":""},{"title":"手机是正品","count":243,"value":1,"attribute":"1020-11","scm":""},{"title":"系统很强大","count":214,"value":1,"attribute":"921-11","scm":""},{"title":"态度不错","count":144,"value":1,"attribute":"10120-11","scm":""},{"title":"款式好看","count":115,"value":1,"attribute":"121-11","scm":""},{"title":"快递不错","count":108,"value":1,"attribute":"420-11","scm":""},{"title":"手感很好","count":90,"value":1,"attribute":"721-11","scm":""},{"title":"性价比很高","count":85,"value":1,"attribute":"20520-11","scm":""},{"title":"性能一般","count":39,"value":-1,"attribute":"921-13","scm":""},{"title":"配件一般","count":35,"value":-1,"attribute":"621-13","scm":""}],"attribute":[{"name":"版本类型","options":[{"name":"中国大陆","value":"中国大陆"}]},{"name":"版本类型","options":[{"name":"中国大陆","value":"中国大陆"}]},{"name":"版本类型","options":[{"name":"中国大陆","value":"中国大陆"}]},{"name":"版本类型","options":[{"name":"中国大陆","value":"中国大陆"}]}]},"skuFull":false,"showPicRadio":true,"isRefundUser":true})最外层是个json_tbc_rate_summary()回调函数,它的参数是个词典,我们词典拿出来,放到python中看起来就比较方便了。
处理结果:

2.4总结
这样一来,随便你怎么造,基本的数据你都能获取到了,动态内容你也有了。正则式也有了,随便搞。看到这里,基本可以爬取一些网页了,下面的内容都是在吹牛,不看也罢。
尽管你都能获取到了,但是效率呢?下面说说怎样高效抓取。
3.高效抓取数据(多线程/多进程/分布式爬虫)
从这儿以后的内容我了解的不深,大部分内容我也在学,权当一起聊聊,说错的地方请及时指出;我尽力说说,重在大家自己的修行。多看书,多学习。
3.1多线程爬虫
以上篇文章《获取爬虫所需要的代理IP》中验证IP可用性来说,当数据库和获取到的数据中有多个IP,假设有1000IP,如果是串行的话,一个个IP去验证,效率非常低了,更何况遇到不能用的还会超时。这里使用多线程,明显提高了效率。
不谈多线程的原理/好处,只说说怎么使用。因为我不会!你来打我呀!
上篇文章中,验证IP时,将IP全部读入列表。多个线程从列表中获取、验证,然后将可用的IP放入词典(主要为了去重)中。这里只是给大家一个思路,还比如,你设置一个或者多个线程专门抓取网页上的链接然后放在列表中,然后多个线程从列表中取/访问链接,这就涉及到生产者消费者问题了。不多说了,大家应该多学学这里,以后用得着。
线程数量多少依据电脑性能来定。
这里使用的模块是threadings,具体怎么用,网上的例子比我说得好,万一我跟他想到一块儿去了,说的一样好了,那不就来指控我抄袭?参考廖雪峰老师的教程:多线程
代码:Github 多线程的使用在GetIP.py文件中。
逻辑图:
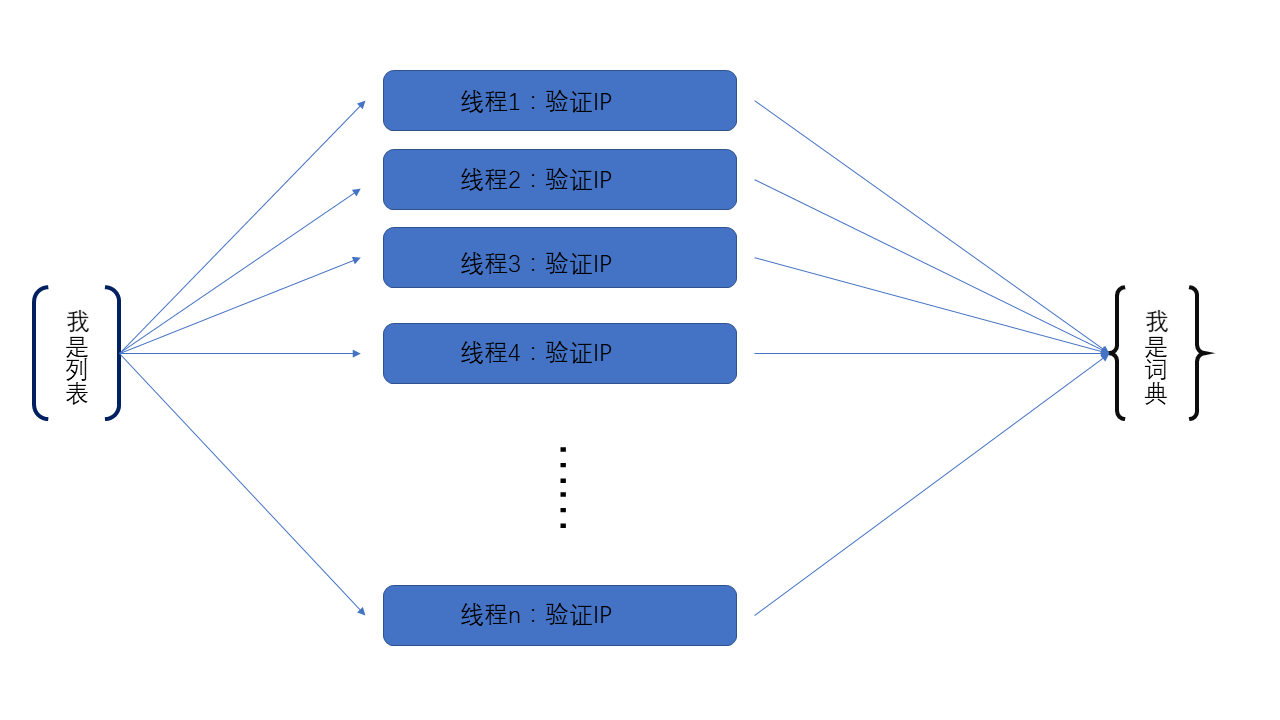
这虽然不是串行,效率提高了好多,但这还不够,我要做你近旁的一株木棉……跑题了,这还不够,并发效率虽然提高了,但是不能有效的利用CPU的多核,经常是1核有难,7核围观。蛋疼的GIL啊。(大家有兴趣可以百度“python 多线程能利用多核吗”)
接下来你需要的是多进程爬虫。多个CPU一起建设社会主义,大步迈入小康社会!
3.2多进程爬虫
如果单单是多进程爬虫,执行效率会提高,再加上协程的话,效率会有明显提高。逻辑结构同多线程类似,只不过进程之间通信要使用Queue或者Pipes。
多进程的使用参考廖雪峰老师的教程
大体结构如下图
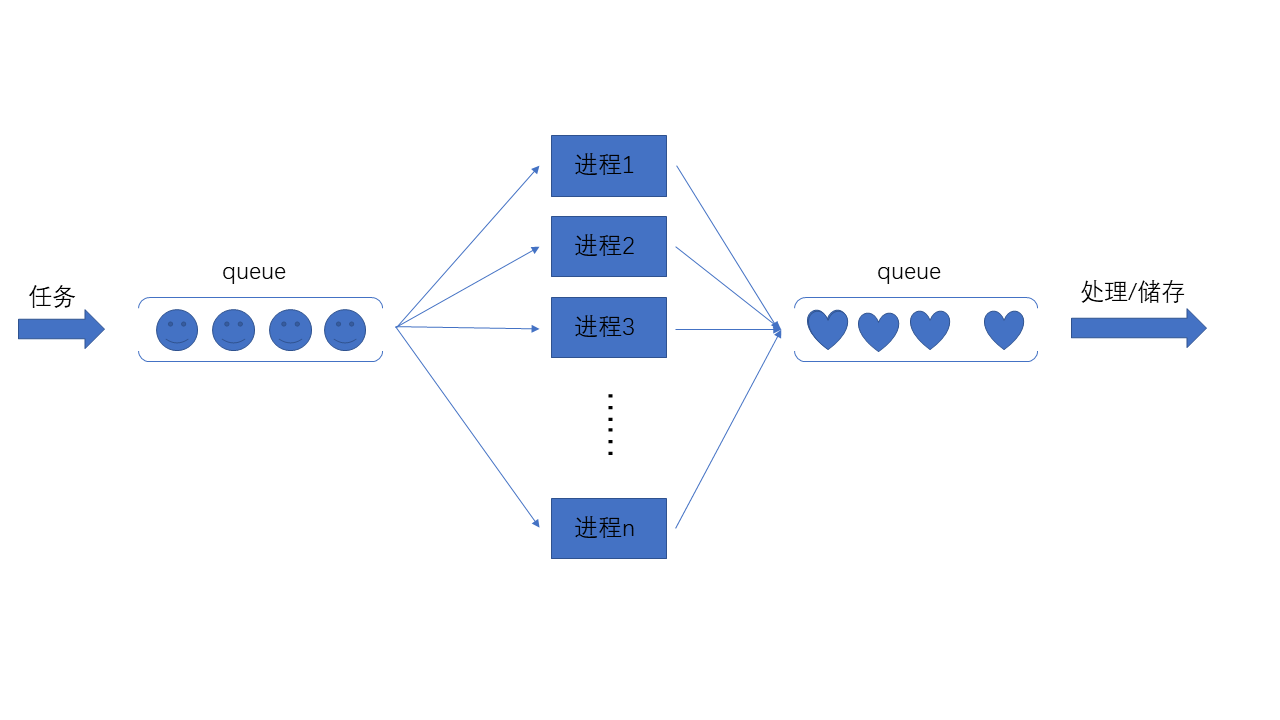
我把那个获取代理IP改写成多进程版本再发出来。
3.3分布式爬虫
当网络带宽、端口资源、IP资源、存储资源满足不了爬虫时,应当适用分布式爬虫,最基本的分布式爬虫结构如下图:
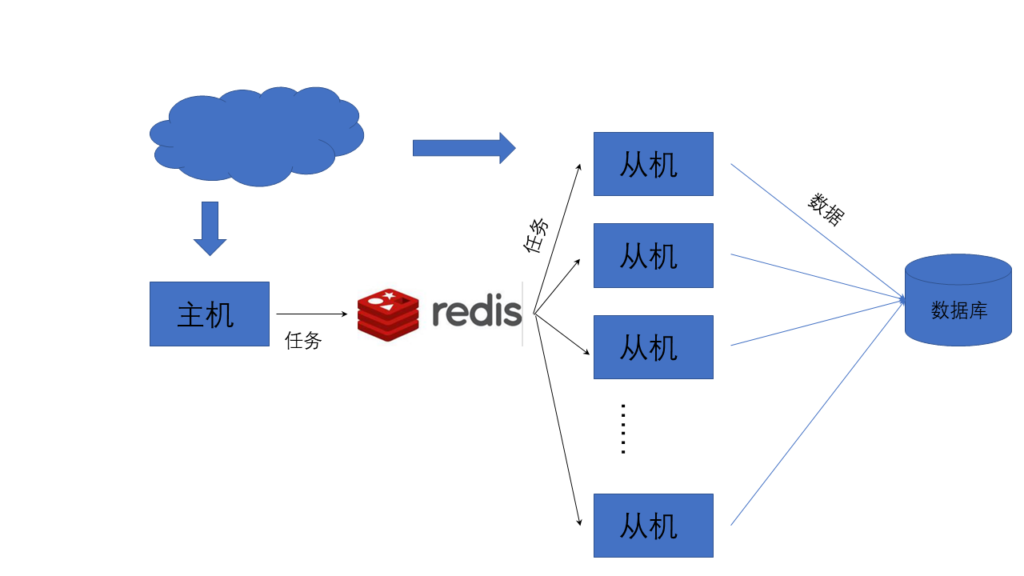
每一个从机上都可以再使用多进程。
我还没写过分布式。推荐一个Github项目,简单的分布式爬虫,爬取知乎用户:ZhiHu Spider based on Python
3.4总结
提升效率的方法:串行->并发->并行->分布式。
提升效率了也得注意公德,别给人家服务造成太大压力,适当的sleep。
4.持续抓取数据(增量式爬虫)
是 指 对 已 下 载 网 页 采 取 增 量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。 和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。——百度百科
举例,拿最热的《战狼2》来说,我要实时获取最新的影评,进行一系列操作,但是不抓已经保存的评论,只检测最新的评论然后获取/处理。知乎上的大神们提到增量式爬虫重点在怎么判断是否抓取过,从而避免重复抓取;再一个就是数据去重。
推荐Github项目:byrSpider
5.爬虫和反爬虫和反反爬虫
爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider),是一场精彩绝伦的战争,你方唱罢我登场。
5.1动态加载
关于动态加载,一种是前面在提到的提取动态内容,方法差不多。另外可以使用selenium/phantomjs提取啊。
因为爬虫不会执行js代码进行渲染,有的可能会使用js代码与服务器通信,回传一定的数据,若是爬虫,这段js代码便不会执行,可以封IP了;或者给你假数据,投毒。
还遇到过,抓取代理IP时,某个网站需要调用API来checkuser,只需要调用,哪怕check失败了;如果不调用的话,就得不到数据。这就跟上面差不多。
这时候用必要使用selenium/phantomjs了,但是会大大降低效率。
还想到的其他反爬虫策略也有改动页面结构。
5.2验证码
当网站判断你是个爬虫时,经常会跳出几个验证码来打断你……的腿。处理验证码,常用的方法有:
1.频率不高,数据量不大时,可以手动输入
2.频率高,数据量大,考虑接入打码平台。你们知道吗,这叫服务,得花钱!
3.当以上行不通时,自己写程序识别验证码啊。我会说我本科毕设做的就是基于深度神经网络的验证码识别吗?会!由于做的不成熟,就不拿出来现眼了。验证码识别在知乎和GitHub上都有相关的项目,可以参考做一下。
4.还有哪些非传统的验证码,例如12306的选择图片、滑块验证、记录鼠标轨迹和点击等等。12306那个可以调用谷歌或者百度的识图API,滑块和鼠标轨迹之类的得借助phantomjs。等我学会了我再讲出来。这里会耗费精力很大。多多sleep会在很大程度上避免验证码。
5.3登录
还在学习这个,懂得不多,不吹牛皮,推荐Github项目:模拟登录一些知名的网站,为了方便爬取需要登录的网站
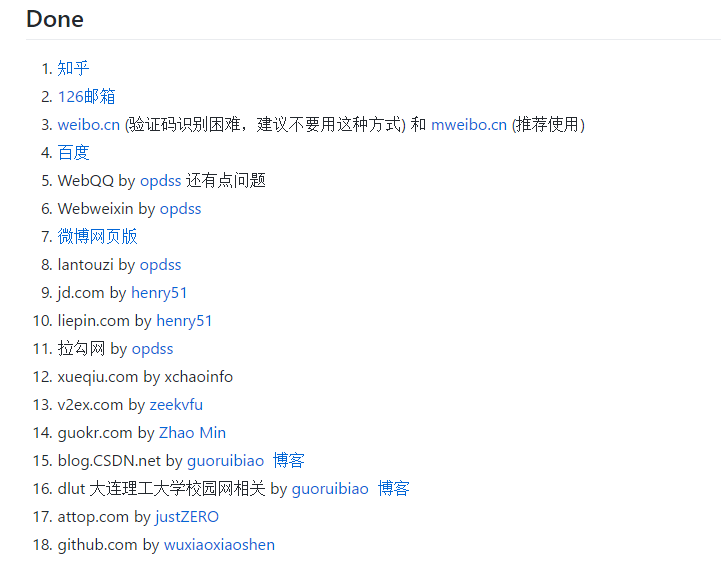
5.4cookie
大多数不是真心想要反爬虫的网站,或者保护重要数据,不会查你的cookie。推荐几篇关于cookie的文章,别的以后想起来再补充。
Find Hao——python爬虫学习(四)获取cookie
州的先生——Python爬虫实战入门四:使用Cookie模拟登录——获取电子书下载链接
5.5总结
其实绕过这些反爬虫手段才是王道,正面刚得费多少精力。间隔时间大一点儿,并发量小一点儿,不给人家服务器造成压力,人家才不会盯上你。出来混都不容易,谁还不是个宝宝。
6.推荐
1.有能力的去阅读Scrapy源码
2.推荐书目:《HTTP权威指南》《用python写网络爬虫》,前端方面我是小白,就知道本《CSS权威指南》求大家推荐基础的前端书籍。
3.python相关的:路人甲大神的python总结,还有知乎上好多python大牛,多多关注他们
4.我这儿还有一些python的电子书,包括网上的和我自己买的,都贡献出来
链接: https://pan.baidu.com/s/1ls3dMt91GQuxdz3OpScbaw 提取码: 1aak
5.正则表达式相关的,我倒是经常看见这个大哥(国服第一奇葩辅助)回答
博主,你的VPS配置是多少的?多少的配置可以满足日常爬虫需要?
我的博客vps是vultr家的,1核512M,挺便宜的,推荐一下https://www.vultr.com/?ref=7170172
如果要单纯用vps部署爬虫,要看爬虫的设计来决定vps配置了。
[…] 简单爬虫的通用步骤 […]
博主写文章的手法有点意思,虽然python刚学,但是看你文章一点也不累,幽默风趣,网络用语用的很好。
多谢支持~
博主,度云链接挂了QAQ
写的浅显易懂,多发啊,全力支持你,比心
还有那个百度云网址没有用了,资料下不了,可不可以发给我啊,感谢
1766845459@qq.com
链接: https://pan.baidu.com/s/1ls3dMt91GQuxdz3OpScbaw 提取码: 1aak
刚看到 不好意思,这是新链接。
谢谢分享,最近想用C++写个爬虫,google参考一下相关知识点。