原文出处:图像识别–传统的验证码识别
作者:知乎–Owen Yu本文已得到作者授权
目前,很多网站为了反爬都会采取各种各样的策略,比较简单粗暴的一种做法就是图片验证码,随着爬虫技术与反爬技术的演变,目前验证码也越来越复杂,比较高端的如Google的I‘m not a robot,极验等等。这些新的反爬方式大多都基于用户行为分析用户点击前的鼠标轨迹来判断是访问者是程序还是人。
这篇文章介绍的是破解一般“传统”的图片验证码的步骤。上面提到的极验(目前应用比较广)也已经可以被破解,知乎上有相关的专栏,我早前无聊的时候跟着做用Java破解过,这里就不重复了。
即便是传统的图片验证码,也是有难度区分的(第一张图是我母校官网上的验证码,基本形同虚设;第二张图则是某网站的会员登录时的验证码增加了一些干扰信息,字符也有所粘连),但是破解的流程大致是一样的。
![]()
图1. 经典验证码

图2. 经典验证码
识别步骤
一、获取样本
从目标网站获取了5000个验证码图片到本地,作为样本。因为后期需要进行机器学习样本量要足够大。
二,样本去噪
1,先二值化图片
这一步是为了增强图片的对比度,利于后期图片图像处理,代码如下(没怎么写过python如果有什么低级错误请见谅):
# 二值化图片
@staticmethod
def two_value_img(img_path, threshold):
img = Image.open(img_path).convert('L')
# setup a converting table with constant threshold
tables = []
for i in range(256):
if i < threshold:
tables.append(0)
else:
tables.append(1)
# convert to binary image by the table
bim = img.point(tables, '1')
return bim
效果如下:
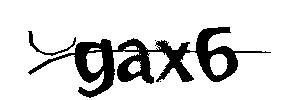
图3. 二值化效果图
2,图片去噪
该案例中就是去除两条干扰线,常规的去噪算法有很多(洪水法等等),这里根据图片的特点采用了两种去噪算法,一种是自己根据图片的特征实现的算法,另一种是“八值法”。去噪后的效果如下,可以看到去除了大部分的干扰线(剩下的根据字宽可以直接过滤掉),但是部分字符也变细了,所以这一步的去噪阀值需要不断调整,在去噪的基础上要尽量保持原图的完整和可读性。
代码如下:
# 根据图片特点,自己写的降噪算法
def clean_img(img, threshold):
width, height = img.size
for j in range(height):
for i in range(width):
point = img.getpixel((i, j))
if point == 0:
for x in range(threshold):
if j + x >= height:
break
else:
if point != img.getpixel((i, j + x)):
img.putpixel((i, j), 1)
break
return img
# 八值法降噪
def clean_img_eight(img, threshold):
width, height = img.size
arr = [[0 for col in range(width)] for row in range(height)]
arr = array(arr)
for j in range(height):
for i in range(width):
point = img.getpixel((i, j))
if point == 0:
sum = 0
for x in range(-1, 2):
for y in range(-1, 2):
if i + x > width - 1 or j + y > height - 1 or \
i + x < 0 or j + y < 0: sum += 1 else: sum += img.getpixel((i + x, j + y)) if sum >= threshold:
arr[j, i] = 1
for i in range(len(arr)):
for j in range(len(arr[i])):
if arr[i, j] == 1:
img.putpixel((j, i), 1)
return img效果如下:
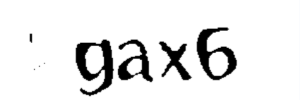
图4. 降噪效果图
三,图片切割
图片切割有很多算法如投影法、CFS以及滴水法等。投影法适用于字符垂直方向上没有粘连和重合的情况,CFS能够很好的切割垂直方向有粘连但是没有粘连的字符,水滴法可以分割粘连字符。目前采用的CFS切割法。切割效果如下图,对于非粘连字符,效果很不错。CFS联通域切割的实现算法主要用的是图的广度/深度遍历,上代码:
# CFS图像切割
@staticmethod
def cut_img(img, threshold, cut_width, cut_height, width_min, width_max, height_min):
charters_imgs = []
width, height = img.size
charters_pixels = []
visited_pixels = []
pixel_arr = ImgTools.get_pixel_arr(img)
for i in range(width):
for j in range(height):
pixel = img.getpixel((i, j))
if pixel == 0 and [i, j] not in visited_pixels:
charter_pixels = Node(i, j, pixel_arr, []).traversal()
visited_pixels.extend(charter_pixels)
if len(charter_pixels) > threshold:
charters_pixels.append(charter_pixels)
for i in range(len(charters_pixels)):
x_min = 0
y_min = 0
x_max = 0
y_max = 0
# 这里是为了处理没有粘连但是垂直方向有重合的字符
width, height = img.size
tmp_img = Image.new('1', (width * 2, height * 2), 255)
for j in range(len(charters_pixels[i])):
x, y = charters_pixels[i][j]
tmp_img.putpixel((x, y), 0)
if x > x_max:
x_max = x
else:
if x < x_min or x_min == 0: x_min = x if y > y_max:
y_max = y
else:
if y < y_min or y_min == 0:
y_min = y
if width_min < x_max - x_min < width_max and y_max - y_min > height_min:
# charters_imgs.append(tmp_img.crop((x_min, y_min, x_max, y_max)))
# 这里是为了将所有的图片切成一样大,便于后期的特征提取
charters_imgs.append(tmp_img.crop((x_min, y_min, x_min + cut_width, y_min + cut_height)))
return charters_imgs
class Node:
x = 0
y = 0
graph_arr = []
visited_neighbors = []
def __init__(self, x, y, graph_arr, visited_neighbors):
self.x = x
self.y = y
self.graph_arr = graph_arr
self.visited_neighbors = visited_neighbors
def traversal(self):
for i in range(-1, 2):
for j in range(-1, 2):
p = self.x + i
q = self.y + j
if (0 <= p < len(self.graph_arr)) and (0 <= q < len(self.graph_arr[0])):
if array(self.graph_arr)[p, q] == 0 and [p, q] not in self.visited_neighbors:
self.visited_neighbors.append([p, q])
next_node = Node(p, q, self.graph_arr, self.visited_neighbors)
next_node.traversal()
return self.visited_neighbors
效果如下:

图5. 分割效果图
四,提取feature并训练特征模型
1,提取feature
每个字符用了40个样本(每个字符都切成了60×60)进行打标签,如果效果不好后续可以增加样本量(由于M大多数粘连严重,所以切出来的M很少,没有达到40个,直接导致后面M的识别结果也很不好)。

图6. 经预处理后的图
2,训练模型
这里采用了libsvm来训练模型,从个样本中预留了1/10个作为训练集,accuracy达到95%。
五,识别效果
先手动挑选了“乍一看”粘连不是很严重的30个样本,进行训练,结果如下,在80%左右。
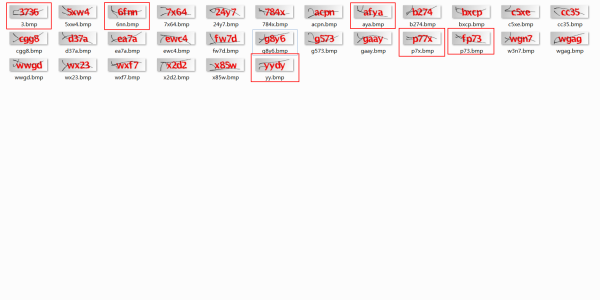
图7. 验证结果
六,总结和优化方向
1,目前整个识别流程已经走通,验证码识别服务也初具对外服务的能力;
2,虽然目前对于整体验证码的识别效果不是很好,但是,验证码服务拼的是识别率,比如说一个验证码需要识别,我在对其进行预处理和切割之后发现字符粘连效果不好,则完全可以抛弃,这并不影响识别率。换句话讲我只是别切出来是四个字符的验证码即可(如果遇到一个网站每个图片的粘连都比较严重,这条路就走不通了);
3,优化方向有两个:(1)优化切割字符的算法,目前的机器学习算法在图片切割比较好的情况下识别率是非常高的,因此目前这类验证码的切割是整个过程中的难点,对于该案例可以采用波斯平滑后通过垂直投影图找到极值点作为水滴法的起点是一个思路;(2)增加样本量,目前是40个识别率已经可以接受,如果增加到100识别率应该会有所提升。
注,分割算法可以参考的文章:
基于惯性大水滴滴水算法和支持向量机的粘连字符验证码识别
lan2720/fuck-captcha 大水滴算法代码实现
学习了
good