
先由一个例子引出主题:最近工作中遇到一个bug,百思不得其解,明明逻辑也通,try/except也没报错,为什么运行结果却不是我想要的?不急着看结果的话,一起猜一下。
大体是这样的,我定义了一个公司类:Company
class Company:
def __init__(self):
self.company_name = ""
self.location = ""
self.phone = ""
self.employee = ""
def __str__(self):
return "company:{}\tlocation:{}\tphone:{}\tname:{}".format(self.company_name,self.location,self.phone,self.employee)每个公司有多个员工,我手上有一串人员名单,就想着每个员工(包含公司信息)当作一条写入数据库里。
于是,我代码是这样写的。
def get_employee_list(company, location, phone, employee_list):
return_employee_list = list()
company_cls = Company()
company_cls.company_name = company
company_cls.location = location
company_cls.phone = phone
for employee_item in employee_list:
company_cls.employee = employee_item
return_employee_list.append(company_cls)
return return_employee_list我就想着用新的employee去覆盖旧的employee,然后直接添加到列表中。代码简洁,很省事,逻辑也没错,但就是出错了。
执行结果:
e_list = ['张三', '李四', '王二麻子']
for item in get_employee_list("Github","USA","Don't know" ,e_list):
print(item.__str__())
company:Github location:USA phone:Don't know name:王二麻子
company:Github location:USA phone:Don't know name:王二麻子
company:Github location:USA phone:Don't know name:王二麻子是不是很意外?
我要是这样输出,你就明白了(前提是不重载__str__())。
e_list = ['张三', '李四', '王二麻子']
for item in get_employee_list("Github", "USA", "Don't know", e_list):
print(item)
<__main__.Company object at 0x000002974444B198>
<__main__.Company object at 0x000002974444B198>
<__main__.Company object at 0x000002974444B198>明白了吧,都是一个对象!
也就是说,使用append往列表中添加的都是同一个对象的引用,而不是一个个独立无关的对象。所以说,我是往列表中添加了同一对象的三个引用。错用C语言的思路写了python。
下面先把程序改过来:
def get_employee_list(company, location, phone, employee_list):
return_employee_list = list()
for employee_item in employee_list:
company_cls = Company()
company_cls.company_name = company
company_cls.location = location
company_cls.phone = phone
company_cls.employee = employee_item
return_employee_list.append(company_cls)
return return_employee_list
company:Github location:USA phone:Don't know name:张三
company:Github location:USA phone:Don't know name:李四
company:Github location:USA phone:Don't know name:王二麻子借着上面,说说python3的对象和引用,内存管理。
首先,仁慈的独裁者告诉世人,在python中万物皆对象。
引用计数
python中变量,应当看作是对象的一个标识,或者是对象的一个引用。当我们像下面一样赋值时,我们会发现,python把变量b当作是test的一个引用处理,也可以叫做浅拷贝(后面会说拷贝相关)。
from sys import getrefcount
a = 'test'
print(getrefcount('test')) #查看 'test'引用计数
b = a
print(getrefcount('test'))
print(id(a), id(b), a is b) #查看a b的内存地址
c = 'test1'
d = 'test1'
print(id(c), id(d), c is d)
#运行结果
4
5
2150002613360 2150002613360 True
2150008644696 2150008644696 Truetips: is和==不能通用,is比较的是内存地址,看两个变量是不是指向同一个对象;==是比较两个变量的值,看两个变量的值是否相等。
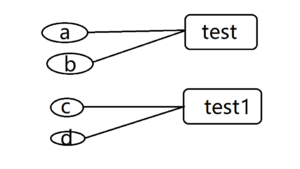
这就是ab变量和’test’之间的关系,看到这里可能有人会问,那我修改a,变量b是不是也会跟着变化?答案是不会,修改a的时候,会重新生成一个对象赋给a。这就是引用计数。
这点跟C语言不同,C会为每个变量都申请一个空间,这也就是为什么a和b的指针不一致的原因(假设上面abcd变量在C语言中)。当然,python3中的变量你也可以看作C语言中的指针。
当然还有以下几种情况会导致引用计数增加:
1.传参foo(a): 这也是python唯一支持的传参方式:共享传参。即形参为实参的一个副本,或者叫实参的别名(也就是一个引用),这样的传参的问题是,参数为可变类型时,修改形参会导致实参发生改变。例如:
def foo(a):
a.append(10)
b = [1, 2]
print(b)
foo(b)
print(b)
#运行结果
[1, 2]
[1, 2, 10]2.将变量作为容器(list、dict等类型)的一个元素。
a = 10 mylist = [1, 2, a]
那么什么情况会导致引用计数减少呢?
1.变量离开作用域了,夭寿啦,离开作用域还不死就没天理了。这时候对象的引用计数会-1,但对象不一定死(可怜你们连对象都没有,我就不一样了,啊哈哈)。
2.对象的一个别名(也就是一个引用)被显示地销毁,del a。
del只能删除引用,引用为0时释放对象
del只能删除引用,引用为0时释放对象
del只能删除引用,引用为0时释放对象
不要再听什么什么使用del直接释放资源。
3.还记得上面说的可变对象的一个引用被修改时,会导致其他引用也发生变化。这里是不可变的引用,不可变的对象,进行修改时,会创建一个新的对象赋给变量,此时原先对象的备胎引用-1。
4.上面说变量作为容器的一个元素时,引用计数+1,自然……时,引用计数-1。
5.引用这个变量的对象直接没了,那这个变量指向的对象的变量就少了一个,这个变量指向的对象的引用计数-1.(其实这句话可以简单说,我偏不,阴天心情不好)
对象的引用计数有增有减,当对象的引用计数减少到0时,已经没有任何引用可以指向这个对象了,用户更不能通过任何方式接触到这个对象了,这时候就该考虑下垃圾回收了。
垃圾回收
当然python也不会频繁的进行垃圾回收,频繁的垃圾回收会导致python工作效率大大降低;那等程序运行结束在进行垃圾回收,很有可能导致内存泄漏。换个中和的方法,python会记录分配对象和取消分配对象的次数,当两者的差值到达某一阈值时,python会启动垃圾回收机制。
也可以使用
import gc gc.collect()
手动进行垃圾回收(一般没有必要)。
达到阈值时,所有对象都会被检测和回收吗?当然不是,python垃圾回收使用的是分代回收,跟页面置换算法中那个最少使用算法类似,对象分为1,2,3代(准确的说应该是0,1,2),刚分配的对象为1,进行垃圾回收时,对象引用不是0,还在使用则对象的代次+1,同时会减少对高代次对象的扫描。
对于循环引用的问题,当你的代码是下面这样的时候

不好意思,放错图了。应该是下面这样时:
a = [1,2] b = a a.append(b)
b引用a,a引用b,子子孙孙无穷匮也。引用计数不为0,永远占在内存里。
python会复制每个对象的引用计数,假设a的引用计数为ref_a,b的引用计数为ref_b,python会遍历a,将a的所用引用对象(这里只有b),对象的引用计数-1(这里只用ref_b – 1)。同理也会遍历b。当遍历结束后,假设某对象ref_x不为0,那么x引用的对象,以及更下游的对象会被保留,其他ref为0的对象会被删除。
上面说了很多对象啊,引用啊,删除啊,释放啊。但是释放后的内存呢?
内存池机制
(能力一般水平有限,这里少做解释,附上一些材料大家有兴趣的去研究下)
python对于小于512字节的内存,会自己管理,避免频繁调用C的malloc/free,造成效率低下。对于不同类型的对象(list、str、dict……),都会有独立的内存池进行管理,不同类型的对象之间不共享内存池。比如当一个整型对象被回收、内存释放,这块内存会被放入整型的内存池中,不能用于浮点数或者列表,下次创建新的整型对象时,再从整型对象的内存池中分配。
python内存管理相关博文:
https://www.cnblogs.com/pinganzi/p/6646742.html#_labelTop
PS:大家想看我写哪方面内容,可以在下面留言,^_^谢谢支持~